At Steeped AI, we've learned that mixing insights with AI can be tricky, one hallucination in a report can break trust. To find the most reliable model for our AI reports, we ran 123 insight-summary tests across 9 models and 6 criteria, performed by former university researcher Tanisha. A majority of the tests, including all for Gemini and GPT-5 were blind to reduce bias.
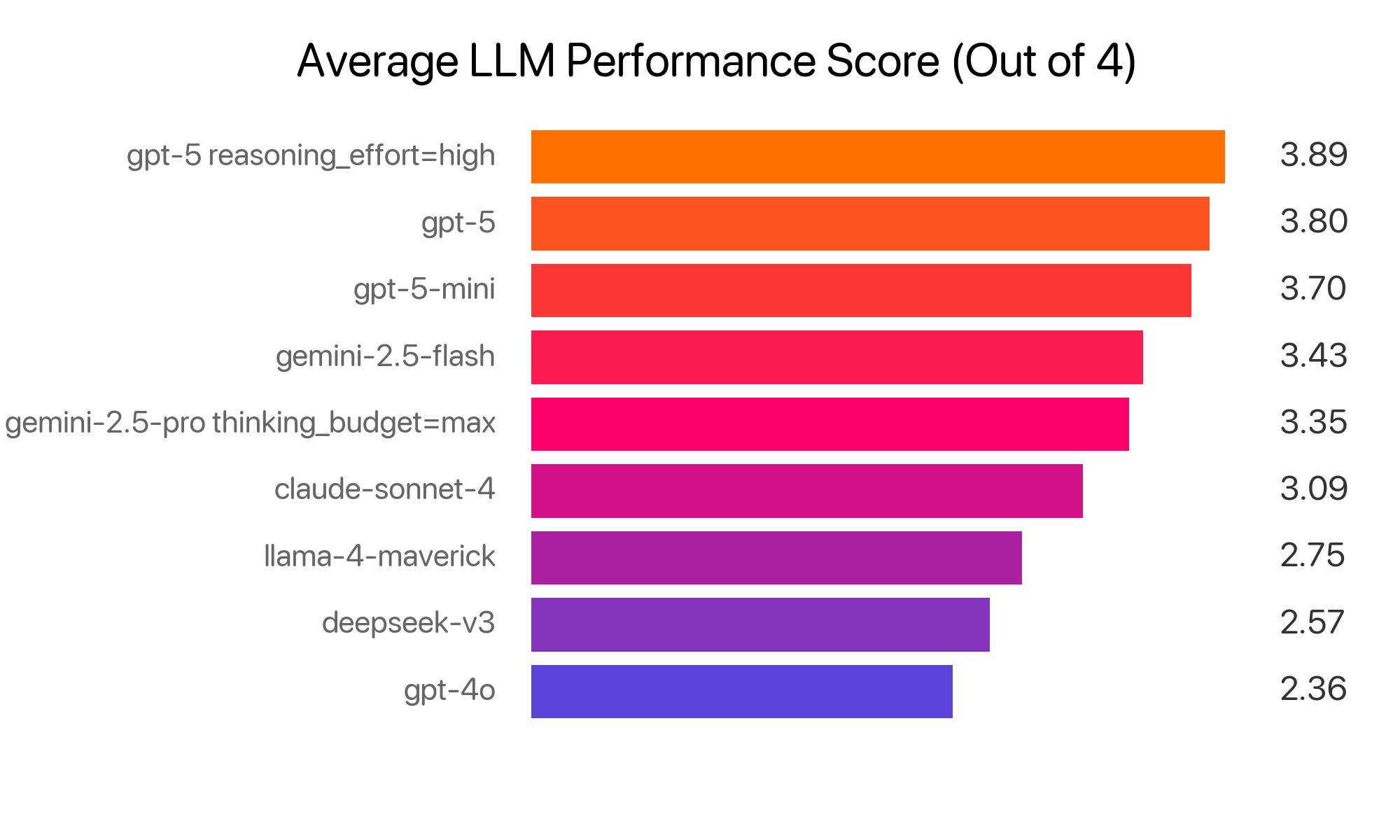
The results were surprising: GPT-5 with high reasoning came out on top, outperforming Gemini 2.5 Pro with max thinking by 16%. Even the base GPT-5 beat GPT-4o by 61%, a huge leap forward. While the tests have some subjectivity, they highlight just how fast the AI race is moving.
Experiment Overview: The Task, AI Models and Grading Criteria
The task that each LLM had to perform was summarizing the key takeaways from a related collection of Steeped AI “Findings” / insights across multiple datasets (surveys and even sales data). A finding is a real calculation from a dataset in word form (from our system not done by AI). Examples:
- “29% of respondents said 'Executive' for "Which department sets the research budget?'”
- or “$127M was the average funding for 'Retail Sector' companies for 'Total Funding Raised'”
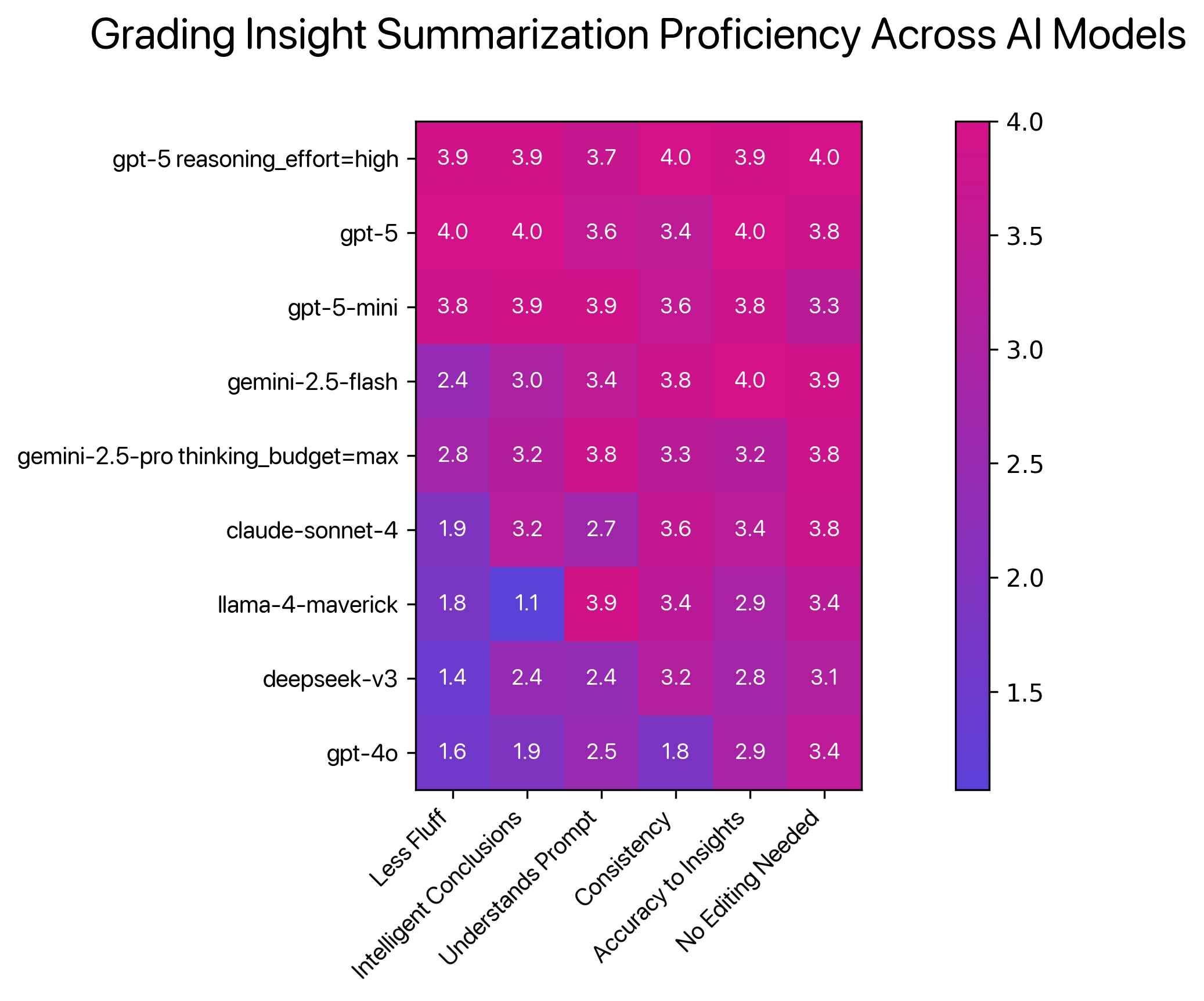
In the 123 tests, each model was graded 1-4 across six criteria, with finding collections varying from 4 to 40 items. To ensure consistency, every collection was tested three times per model. The tests were subjective in that they were run by a single evaluator and focused on findings and criteria relevant to Steeped AI’s business needs.
We tested these AI models through api calls:
- OpenAI: gpt-5, gpt-5 reasoning_effort=high, gpt-5-mini, gpt-4o
- Google: gemini-2.5-flash, gemini-2.5-pro thinking_budget=max
- Anthropic: claude-sonnet-4
- Meta: llama-4-maverick
- Hangzhou DeepSeek AI: deepseek-v3
The 6 criteria were focused on signals that we deemed were indicative of “good insight takeaways” in a report:
- Less Fluff: Doesn’t add flowery transitions and bloated opening/closing statements that do not add value to the report (i.e. “This survey had intriguing insights.”, yawn).
- Intelligent Conclusions: Able to suggest smart next steps and conclusions for the audience, with a broad grasp of complex topics, without misleading or hallucinating.
- Understands Prompt: Accurately follows prompt including character count (within 2,000 characters), information about paragraph structure and general instructions.
- Consistency: When given the same prompt and findings three times, does the model produce consistent answers? This includes summarizing the same findings, performing similar calculations, drawing the same conclusions, and recommending similar next steps.
- Accuracy to Insights: The summary references of insights are spot on in terms of what the insight actually means. No hallucination or misleading statements.
- No Editing Needed: Since the goal is meeting-ready reports, we checked for spelling and grammar, flow, word choice, and clarity for the target audience. We didn’t want the model outputs to sound robotic.
Results: GPT-5 Models in Top 3
Overall, GPT-5 earned the highest average scores, with GPT-5 + high reasoning leading the pack. However, both GPT-5 + high reasoning and Gemini 2.5 Pro + max thinking showed an “overthinking” effect, underperforming in accuracy compared to their lighter counterparts. These models produced strong conclusions and next steps but sometimes overgeneralized, blurring the line between intelligent next steps and misleading hallucination.
Insight summary performance correlated highly with model release date. GPT-4o, the oldest, ranked lowest despite all the hype over the last year. It feels like an arms race, with each company leapfrogging the other quarter by quarter, and overall AI quality rapidly improving.
Here's what we observed across each model:
gpt-5 reasoning_effort=high: The heavy-brain champion
- Release Date: August 7, 2025
- Strengths: Best scores overall on average. Had the best scores for the consistency, no editing needed and strong scores for less fluff, intelligent conclusions and accuracy to insights. The interpretation included mathematical analysis and provided research-based next steps to avoid misleading the audience.
- Weaknesses: Underperformed gpt-5 mini in the understands prompt criteria and gpt-5 (base) in accuracy to insights (overthinking problem).
- Common tells/Other notes: Has the voice of a smart, no-nonsense researcher, which is exactly what we want! It has surprisingly few em dashes and is a big fan of using “-” as bullets + sub-bullets, numbered lists and sections.
gpt-5: The no-nonsense strategist
- Release Date: August 7, 2025
- Strengths: It scored highest on accuracy, concise reporting, and intelligent conclusions. It stuck to the facts without the “overthinking” issues seen in its more advanced cousin. GPT-5 variants also outpaced all other models in reasoning about discussions, implications, and next steps.
- Weaknesses: Underperformed gpt-5 mini and high reasoning in the understands prompt and consistency criteria.
- Common tells/Other notes: Used technical language but demonstrated solid research practices to avoid misinterpretation. Frequently overused em dashes in reports. Always structured summaries as 1-4 titled sections with bulleted findings.
gpt-5-mini: The little model that could
- Release Date: August 7, 2025
- Strengths: Tied for the best score in understanding prompt with high scores in less fluff, intelligent conclusions, and accuracy to insights. On average it comes in at #3 across all criteria and outperformed Gemini and Claude which is meaningful.
- Weaknesses: Underperformed gpt-5 (base & high reasoning) in all categories except understands prompt. Had spelling errors, overly flowery language and words that did not fit the context of the analysis.
- Common tells/ other notes: Like GPT-5 with high reasoning, it rarely used em dashes.The LLM favored executive summaries at the top and, like base GPT-5, used titled sections with bulleted findings.
gemini-2.5-flash: The confident Gemini
- Release Date: June 17, 2025
- Strengths: Highest score in accuracy to insights and strong score in consistency and no editing needed criteria.
- Weaknesses: Underperformed all GPT-5 models in understands prompt, less fluff and Intelligent conclusions criteria. Added unnecessary descriptive language, transitions and went over the character count consistently. When it made a questionable call, like using the word “percentage” instead of “%”, it would stick to it throughout the report.
- Common tells/Other notes: It was very consistent with the format of creating a title for the report at the top and a few dense paragraphs.
gemini-2.5-pro thinking_budget=max: The reserved, overthinking Gemini
- Release Date: June 17, 2025
- Strengths: Strong score in no editing needed and understands prompt criteria.
- Weaknesses: Unlike Gemini-2.5-Flash, adhered to character counts but still used unnecessary descriptive language and transitions. Overthinking was evident in overgeneralized summaries, hurting accuracy scores.
- Common tells/Other notes: If findings did not fit the narrative, the LLM did not include them in the report. Like its flash counterpart, it would consistently create a title and then a few dense paragraphs.
claude-sonnet-4: The verbose, natural sounding model
- Release date: May 22, 2025
- Strengths: Performed strong in no editing needed criteria and tied gemini-2.5-pro thinking_budget=max in intelligent conclusions.
- Weaknesses: Had lower scores in understands prompt, intelligent conclusions, and less fluff. Lengthy opening statements without much relevant content in the reports often overshot the instructed character count. One report had an unacceptable insight hallucination and it shockingly mixed up metrics for Gen Z with Gen X.
- Common tells/Other notes: Was the only model that had ALL CAPS for section titles and would put one paragraph after each section title. Overall, there typically was 5-6 sections.
llama-4-maverick: The best listener that lies
- Release date: April 5 2025
- Strengths: Tied for highest score with understanding the prompt criteria and had a strong score in no editing needed.
- Weaknesses: Lowest score in intelligent conclusions criteria. The LLM could summarize findings, but it showed poor analytical ability and was unable to draw conclusions or suggest next steps beyond restating findings. It also made metric errors, hallucinated content, and mixed up Gen Z with Gen X.
- Common tells/Other notes: It seemed to have the most compact reports out of all the models with short 3-5 paragraphs.
deepseek-v3: Consistently independent
- Release date: December, 26, 2024
- Strengths: Its highest score was consistency and it outperformed llama-4-maverick in intelligent conclusions criteria
- Weaknesses: It was the only model that kept using markdown formatting (like bold “**”) despite clear instructions against it. The LLM consistently went over character limits but provided its own incorrect character counts. Like Claude, it mixed up Gen Z and Gen X metrics.
- Common tells/Other notes: It had the most random formatting, switching between bullets, numbered lists, and medium paragraphs across reports. It used parentheses more than any other model and occasionally added em dashes.
Gpt-4o: Showing its age, but still kicking it
- Release date: May 13, 2024
- Strengths: Outperformed deepseek-v3 in less fluff, understands prompt, accuracy to insights and no editing needed criteria.
- Weaknesses: Lowest performing model on average. Often produced flowery language without meaningful content, misinterpretations and misleading conclusions. It consistently made mathematical reporting errors with the metrics in the findings.
- Common tells/Other notes: Surprisingly, we couldn’t spot one em dash. It was consistent in creating 3-5 short to medium paragraphs unlike its GPT-5 counterpart. The model used quotations the most out of the rest.
Overall Takeaways from Testing AI for Takeaways
AI is getting better and competition is strong: Not really a news flash for anybody paying attention. OpenAI’s flagship model improved by 60% between summer 2024 and summer 2025: a striking pace of progress in insight summary generation. Before GPT-5 launched, models like Gemini, Claude, Maverick, and Deepseek were already surpassing GPT-4o. Just last month we were frustrated enough with 4o to try alternatives, but now we can’t get enough of GPT-5.
GPT-5 is consistent and no nonsense: We actually like this at Steeped AI. Less personality + less extra information + consistent outputs for tasks = less hallucinations which benefits corporate api users like us that do many calls to automate processes.
Persistent Weaknesses: Despite rapid progress, many models still share common shortcomings. They often produce fluffy messaging with little real value, and most struggle to fully understand prompts or build clear next steps from context—showing that more intelligence is still needed in these areas.
Hallucination Remains a Risk: Most models still produce occasional hallucinations, which is a major problem when clients rely on insights to make decisions. At Steeped AI, we address this by embedding numbered subscripts in reports that link directly to the underlying findings and calculations at the bottom of the report. This lets clients easily cross-check AI takeaways against the real, non-AI data.

